Apps, Jobs, Watchers
An Octostar App is executed in its own container, optionally using a custom image, within Kubernetes. But how does it work in detail?
App deployment
In Kubernetes, a Job is a controller object that represents a finite, one-off task that runs to completion. It creates one a Pod and ensures that it successfully terminates. Restarting it multiple times if crashes.
Well, when you "deploy" your app in Octostar, our API defines and instantiates a Kubernetes Job that typically never completes (unless you instruct it to).
An Octostar App is a resilient process, with the following guarantees:
- Will be restarted on crash, yet avoiding crash loops with a backoff strategy.
- Will get executed on another Kubernetes cluster node in case of failures
- A unique URL will be associated to the app
- HTTP connections will be forwarded to the internal port 8088 TCP
- Secrets can be associated to the app (API keys, SSH keys, etc)
- The necessary environmental variables will be provided automatically for the Octostar Python SDK autoconfiguration
Subordinate Jobs
An Octostar app can consume the Octostar API directly, or via the Python SDK.
One of the features in the API is the ability to request the on-demand execution of another instance of the current app. Potentially specifying a custom entry point command. For example a specific Python script, with some specific arguments.
This is useful when the app at hand intends to allocate extra compute/memory resources to parallelise resource intensive executions.
Important
Refrain from spawning subordinate jobs if you intend to parallelise IO bound operations. You won't need more memory or CPU in this case, just find a way to parallelise your code within your main app container.
Subordinate jobs will all be terminated when you un-deploy your app. Alternatively, kill them one by one in the JobsManager UI.
Here is an example of app code (using octostar-python-client) that spawns subordinate jobs.
from octostar.utils.jobs import execute_new_job
from octostar.utils.notifications import toast
for id in to_process:
execute_new_job.sync(commands=[f"bash heavy_worker.sh -i {id}"])
toast.sync(message=f"🚀 New job launched for id {id}")
Secrets
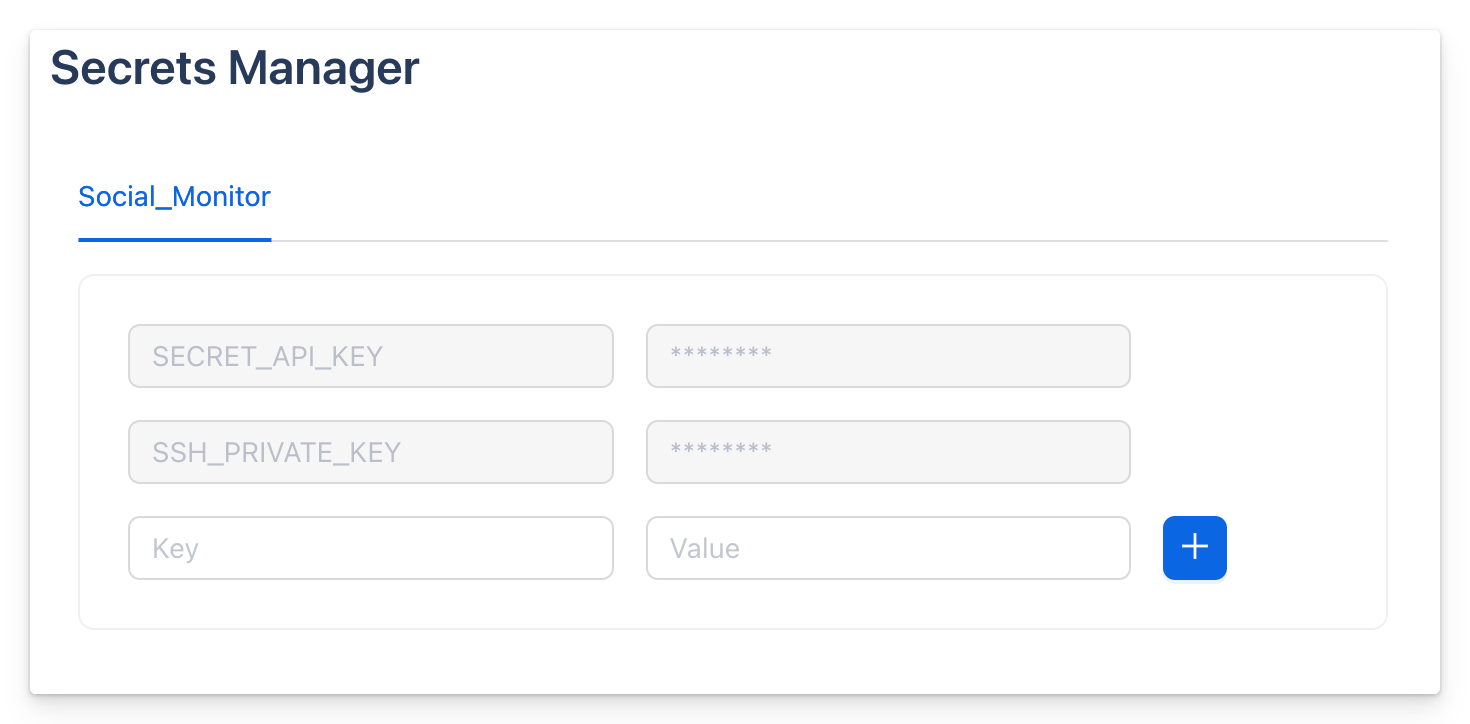
Using "Secrets Manager" You can save app-specific secrets using Octostar App editor. This key-value store is backed by the equivalent data structure in Kubernetes, called Secret. This is an object that contains sensitive data such as passwords, OAuth tokens, SSH keys, etc. Secrets provide more control over how sensitive information is used and reduce the risk of accidental exposure.
Watchers
An app may declare in its manifest one or more watcher functions. Once this app is deployed, a user can create "watcher intent" entities in workspaces. These special entities represent the intent of a user to periodically run a specific watcher function (at the interval defined in the manifest, for example every 20m).
When you deploy an app containing some watcher functions, Octostar creates an underlying Kubernetes CronJob.
A CronJob in Kubernetes is a "wrapper" concept to the regular Job , but specifies to run jobs at scheduled times or intervals. It's like the Cron utility in Unix-like systems but distributed, and resilient like a Kubernetes job. In practice, each CronJob creates Jobs on a time-based schedule.
Creating intents
There are mainly two ways to create intents for watcher functions to consume:
Intents about entities, using the core octostar UI. In this case the arguments field in the intent entity will automatically contain the base64 JSON representation of the entity at the time of intent creation.
Octostar will create also a relationship between the watched entity and the watcher intent (which is also an entity). Let's visualize this using our Link Chart
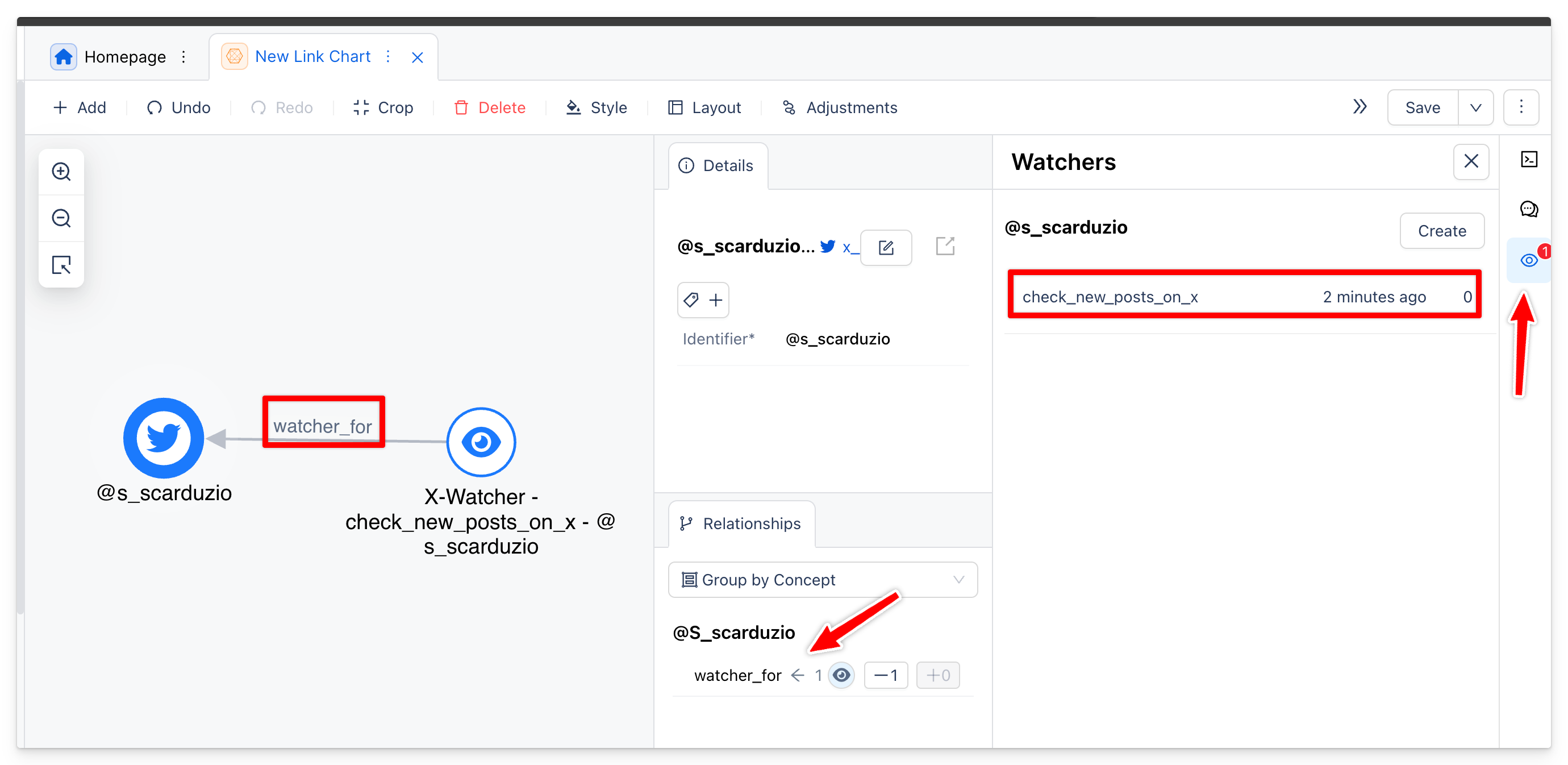
But an app can also programmatically create a custom watch intent entity, which may not be related to another workspace entity.
For example, an app developer may decide to ask for a custom identifier in a form from the app web UI. As long as the intent is marked with the field "watcher_name": "<watcher function name>" it will be picked up by the scheduled executor.
Watchers are powerful, but not wasteful
Let's see why this Kubernetes-native approach to scheduled execution is not wasteful of resources.
- CronJobs do not reserve resources, only when it's time, they will schedule one Job which will allocate resources.
- The Job periodically created for a watcher function will query for all intents to be processed, and will go through all of them in batch. So yes: we can handle a large number of intents within a single job execution.
- The Job will re-utilise the main app's image (cached), simply will invoke a different entry point command/script. This is why having 1000 watcher functions declared won't kill docker daemon.
- The CronJob we schedule does NOT allow for parallel execution. If it takes 20m for executing a watcher function with interval 10m, the next execution will be postponed when the first one finishes.
- Every time a watcher function "wakes up" allocates resources, yes, but will batch process any number of intents in a loop before exiting. So yes, you can have 20K intents and Kubernetes won't explode.